
06/04/2015
3843 views
Defining an Algorithm - Part 2
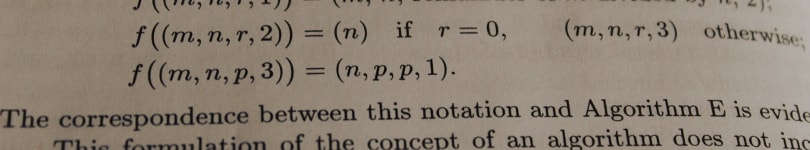
At the end of my Defining an Algorithm article, I said that my next instalment would be to go through the example of a mathematical implementation of Euclid's algorithm that is at the end of the Algorithms section in the first chapter of The Art of Computer Programming - Volume 1. And that is exactly what I am going to do. If you've not already read the previous instalment, I suggest that you do that first in order to fully understand the example we are describing in this article.
So, let's get straight to it. The next line in the chapter, after our last article left off, states the following;
Algorithm E may, for example, be formalized in these terms as follows: Let Q be the set of all singletons (n), all ordered pairs (m, n), and all ordered quadruples (m, n, r, 1), (m, n, r, 2), and (m, n, p, 3), where m, n, and p are positive integers and r is a nonnegative integer. Let I be the subset of all pairs (m, n) and let Ω be the subset of all singletons (n).
Now, first things first, I am going to presume you understood the workings and purpose of Algorithm E (Euclid's algorithm) explained to us earlier in the chapter. If you haven't already, this would be a good time to go back and familiarize yourself with it.
So, as we know from the previous article Q represents a collection of all possible states of our algorithm, including our inputs, outputs and everything between the two. Q contains I and Ω, which are out inputs and outputs respectively. All Knuth is doing at this point is declaring what variables (in groups) represent the various stages of Euclid's Algorithm. As we know Euclid's Algorithm takes two positive integers, which are represented together as the pair (m, n), as our input. When it's done it gives us a single integer, the greatest common divisor of m and n, which Knuth declares as being represented by the singleton (n). So what do we have left unaccounted for at this point? Well, we have the quadruples (m, n, r, 1), (m, n, r, 2), and (m, n, p, 3). They represent the steps in between, the states of our variables, during the process of working out our largest common divisor. Then the difficult bit, the computational rule is defined.
f((m, n)) = (m, n, 0, 1); f((n)) = (n);
f((m, n, r, 1)) = (m, n, remainder of m divided by n, 2);
f((m, n, r, 2)) = (n) if r = 0, (m, n, r, 3) otherwise;
f((m, n, p, 3)) = (n, p, p, 1).
When I first looked at the above, I remember thinking that I would never understand it. The only way I managed to finally get to grips with it was by attempting to use the functions to get an expected result. Once I've described how it all works and what it means I implore you to try and use it to work through a few examples yourself until it sticks. Human beings learn through doing, not just through reading. Each statement, ending in a semicolon (' ; '), is a definition of what the function will do with certain arguments. Each argument is of course one of the states of the computation, and as we know from Knuth's formal definition we pass our states back into our function to get the next state, until we get our end results or output (which will not change if passed back into the function).
Our first statement f((m, n)) = (m, n, 0, 1); defines what our function (or computation rule) does with the initial input m & n. So this is where we start, and from looking at it we can see that, taking our input ((m, n) pair from I) our function converts it to one of the quadruples (one of the intermediate states). Nothing has been done to m and n, so they remain the same, but now we also have 0 and 1. The 0 is just filler, and the 1 seems to represent the step to be performed next. So, now we have a quadruple which needs to be passed back into our function to get the next state. At this point, take a look at the formula above, and look for what our function would do to our result. If we pass our 0 into the variable r then the statement on the next line down fits the bill perfectly: f((m, n, r, 1)) = (m, n, remainder of m divided by n, 2);. You can see at this stage that we've done the division to find the remainder and now, we have a new intermediate quadruple, which can be passed through our function again using the definition on the third line of the formula. The third line statement checks whether the remainder calculated in our last step is 0, if so it converts our quadruple into the singleton (n). If that is the case then that is the end of our process. Passing the singleton (n) back into the function will not change it. (n) is our output (the largest common divisor). If our remainder is not 0 then we get another quadruple, which is passed into the statement on the last line of the formula. All this does is re-arrange the variables to pass them back to our function as f((m, n, r, 1)), and we start again. The re-arranging of the variables is essentially the replacing of m with our old n value, and then replacing n with the remainder (as per our original definition of Euclid's Algorithm).
Now at this point, in order for it to actually sink in, I think it's prudent to go through an actual example with our example algorithm. Imagine we want to find the largest common divisor of our pair (6, 4). This is our input (m, n). Passing this into our input gives us f((6, 4)) = (6, 4, 0, 1);. This is our second line in the formula. Pass our new quadruple to the third line and we get f((6, 4, 0, 1)) = (6, 4, 2, 2); where the first 2 is the remainder of 6/4. So now we pass it back in again and get f((6, 4, 2, 2)) = (6, 4, 2, 3); because the remainder was not 0. And lastly, it get passed to the bottom line in the formula and we get f((6, 4, 2, 3)) = (4, 2, 2, 1);. Now we have re-arranged our variables so that m <- n and n <- r and passed it back to the second line in the formula. And now we go around again. Now we do f((4, 2, 2, 1)) = (4, 2, 0, 2) because 0 is the remainder of 4/2, and then f((4, 2, 0, 2)) = (2) because our remainder was 0 and we therefore have our answer which is 2. This all looks a little something like this;
f((6, 4)) = (6, 4, 0, 1); f((6, 4, 0, 1)) = (6, 4, 2, 2); f((6, 4, 2, 2)) = (6, 4, 2, 3); f((6, 4, 2, 3)) = (4, 2, 2, 1); f((4, 2, 2, 1)) = (4, 2, 0, 2); f((4, 2, 0, 2)) = (2); f((2)) = (2);
It's worth restating at this point, that the last number in the quadruples indicates how the function will work on it next. Before we move onto the next bit, sit down and work through a few of your own examples. If you think you've got it already, try working through something much more complicated than starting with 6 and 4.
I think that's enough for this instalment. Next, Knuth mentions that this system doesn't restrict defined Algorithms to strictly effective ones, where there are a finite number of steps or where the steps can always be performed by a human being. He then goes onto describe a second implementation of Algorithm E, using Markov algorithms that doesn't have this issue. In our next instalment, I will be describing what those are and how they apply to the next few paragraphs.
I hope this was helpful. Thanks for reading. If you have any criticism, corrections, objections, or (Gods forbid) praise just drop me a comment under the article, and until my next article, happy reading!